Understanding how Structr worksFundamental Concepts
This chapter covers the following topics:
Rendering Engine
The Document Object Model (DOM) specification defines a data model and standardized access methods for structured documents like HTML and XML. Structr uses the DOM to store its pages in the database.
You can see this DOM structure in every page in the Pages area. This is not just a visual development aid, but reflects the actual data in the database. More precisely, a page is literally stored as the structure of its DOM tree inside the graph database, i.e. each node in the DOM tree is stored as an individual node in the database, connected by edges expressing their parent-child relationships.
Rendering Process
When a user accesses the URL of a page with their browser, a process is started that runs through this tree structure from top to bottom and generates the HTML representation for each element. This process is called page rendering. Because of this sequential processing, it is possible to run through the same element more than once without additional effort (e.g. for each result of a database query) or to hide the content of specific elements depending on certain conditions (for access control). Together with the template and scripting language available in Structr, this creates an intuitive and extremely flexible rendering engine.
HTML elements
The HTML5 standard defines different types of elements: the so-called “block elements”, e.g. <div>, <p> or <table> that form the structure of a document, and “inline” elements like <a> and <span>, etc. The content of an element can be other elements, or so-called #text nodes as defined in the DOM specification.
Content Elements
The DOM #text nodes are called Content Elements in Structr. They contain the actual text content of elements. The text in such an element can be displayed differently depending on the content type set. In addition to plain text and HTML, different dialects of markup languages such as Markdown, Textile and other Wiki formats are supported, which allow automatic formatting of annotated text.
Content Types
Structr supports various different content types in Content Elements. Setting the content type of an element to a value other then text/plain causes the element to behave differently.
You can for example use the following text in a content element with the content type text/html to display special characters from the UTF-8 character set.
▸ first bullet point
▸ second bullet point
▸ third bullet point
Which results in the following output.
▸ first bullet point
▸ second bullet point
▸ third bullet point
text/plain
A content type of text/plain (which is the default) renders the literal element text to the output document. That means that characters with special meaning in HTML will be replaced so that they are not interpreted by the web browser.
<h1>text</h1>
will be written in HTML as
<h1>text</h1>
so it shows up on the HTML page in its literal form.
text/html
A content type of text/html renders the element text to the output document without changing it. That means that characters with special meaning in HTML will not be replaced, causing the web browser to interpret them as a part of the HTML code of the page.
This content type must be set on template elements or content elements that are included using the built-in include() function, and on so-called Main Page Templates that use ${render(<a data-id="3230f1d81eb345c199024b82eb7c56f2" class="mention">children</a>)}.
text/markdown
A content type of text/markdown writes the element text to the output document using a Markdown Formatter. Markdown is a simplified markup language that uses common text formatting techniques to create structured documents that are readable without additional formatting or interpretation, but can also be converted to styled HTML or PDF documents.
See https://www.markdownguide.org for more information on the Markdown syntax.
Structr uses the FlexMark Markdown Formatter from https://github.com/vsch/flexmark-java/wiki/Markdown-Formatter.
Template Expressions
To dynamically generate content during rendering, Structr provides a mechanism for opening a scripting environment within a content element. For these so-called template expressions, Structr uses a syntax similar to the Freemarker Template Language.
Keywords
In addition to the built-in functions provided by the scripting environment, Structr introduces a set of predefined keywords in the template elements that allow access to data in the current context, for example the logged on user, the current page, or any existing request parameters.
For complex processes within a template JavaScript can be used, because there are no directives or extra flow control elements in Structr templates unlike in Freemarker. Structr offers a very similar concept, show conditions, which are discussed in more detail in the “Visibility” paragraph below.
In addition to JavaScript, a simplified script language called StructrScript is also supported, which is particularly suitable for short script expressions as well as simple text formatting and variable replacement.
For instance, consider the following simple example, which prints the name of the logged in user.
A server-side JavaScript example
${{
// fetch the current user
const user = $.get('user');
// print user name
$.print('Logged in as: ', user.name);
}}Template Elements
As defined in the DOM specification, Content Elements must not have child nodes. To be able to mix template expressions and node structures, Structr provides a block-version of Content Elements, the so-called Template Elements (![]() ). Similar to Content Elements, Template Elements support different content types and allow for template expressions. However, in contrast to Content Elements, Template Elements can have children.
). Similar to Content Elements, Template Elements support different content types and allow for template expressions. However, in contrast to Content Elements, Template Elements can have children.
As described above, the rendering engine’s default behavior is an in-order traversal of the DOM tree, rendering each element as it is visited. However, when encountering a template element, this behavior does not make much sense, as the template element may require it’s child elements to be rendered in specific positions of the script.
Therefore, the rendering flow stops at template elements and does not render the remaining branch of the DOM tree. Instead, the template element has to explicitly invoke the rendering process for it’s child elements in the appropriate place. To accomplish this, Structr provides the children keyword and the render() function, as shown in the example below. While this makes the configuration of template elements a bit more subtle than that of content elements, it provides much more flexibility.
Rendering the children of a Template Element
${{
// fetch the templates child elements
const children = $.get('children');
// render the child elements
$.render(children);
}}Shared Components
A Shared Component is a reusable structure of HTML elements that can be inserted into a page via drag & drop. It is very similar to a Widget, but there is one important difference: when you insert a Shared Component into a page, Structr creates a special element in that page that relays the rendering to the original Shared Component. This means that changes are immediately visible on all pages where the component is present.
To customize Shared Components you can use the auto-script property sharedComponentConfiguration on the linked node. If present, the script expression in this property will be evaluated before the rendering continues with the shared component.
Widgets
A Widget is a reusable piece of HTML code that can be inserted into a page. You can make Widgets configurable by inserting config expressions in the widget source and adding the expression into the configuration. Widget config expressions look like this [configSwitch] and can contain any characters (except the closing bracket). If a corresponding entry is found in the configuration, a dialog is displayed when adding the widget to a page.
When dragging a Widget into a page, a new set of DOM elements is created as child nodes of the node the Widget was dropped onto, including metadata defined in the Widget source like data binding and queries. The textual information contained in the Widget is transformed into database elements (nodes, relationships and properties) as well.
Once created, the new DOM elements have no connection to the Widget they originated from. Later changes made to the Widget code don’t effect on the page’s elements. Widgets in Structr are more or less containers to exchange reusable code between Structr instances.
Widgets can also contain Cypher statements to create or modify graph objects on database level.
Visibility
Since a page and all its elements are represented by nodes in the database, access to these elements can be controlled with the standard Structr node-level security model: each node has an owner and two switches that control read-only access, visibleToPublicUsers and visibleToAuthenticatedUsers.
For HTML elements, Structr offers two additional ways to control the visibility during page rendering: showConditions and hideConditions. Both can contain a StructrScript or Javascript expression and - if they are filled - are evaluated before rendering. Depending on the return value of the script, the current element and its substructure will be displayed or hidden. Both fields are auto-script environments, i.e. the text in those fields is interpreted as a script without the need for the template expression markers ${...}.
Data Binding
The Page Rendering Engine allows developers to create dynamic markup elements by binding a scripting expression or database query to an element in the markup tree. A dynamic markup element is called a repeater. It is rendered to the output stream once for each object in the query or function result collection and will be displayed including its substructure. The current element can be accessed through a keyword, the so-called data key. The data key is valid in the entire subtree within the repeater element and can also be referenced in content nodes, templates or element attributes.
Scripting
Structr provides a comprehensive scripting framework that enables the implementation of business logic and supports a variety of scripting languages. The possible applications range from implementing type-specific logic, retrieving and transforming data from a UI or external interfaces, controlling visibility of elements in pages, rendering content and more. These possibilities make scripting in Structr a powerful and versatile tool.
Structr distinguishes between two kinds of scripting contexts: Explicit or manual contexts that have to be defined by enclosing code in ${} and implicit or auto-scripting environments that are automatically defined and directly interpret code without surrounding curly brackets. Please refer to further documentation for areas that support auto-scripting.
Supported Languages and Environments
Depending on the context, different kinds of Scripting environments and scopes are possible. In auto-scripting environments, Structr will automatically assume any code to be StructrScript, unless otherwise specified. Within this context, it’s possible to define other scripting environments by using a special notation similar to how explicit scripting contexts are defined. These special notation is further explained in the section for each specific scripting language.
StructrScript
StructrScript is the name of the internal scripting language that can be used in Content or Template nodes, Template Expressions, Show Conditions and HTML attributes. It is a simple interpreted functional scripting language that provides access to Structr’s functionality through a set of functions and keywords. StructrScript has no control structures, it is interpreted like a fully functional language, although some of the Built-In Functions have side effects.
A StructrScript context is explicitly defined by ${} and automatically assumed within auto-scripting contexts.
The return value of a StructrScript expression is determined by resolving the nested functions from the inside out.
Example
join(extract(find('User'), 'name'), ', ')The above example shows the use of three different built-in functions. The find() function executes a database query and returns the result collection. extract() converts the collection of database objects into a collection of strings and join() concatenates the collection of strings into a single string, using the given separator between the elements.
Built-in Functions
Built-in functions provide access to the Structr Backend API from within a scripting context. You can run database queries, process the results, create or modify objects, and much more.
JavaScript
JavaScript scripting contexts are explicitely defined by enclosing dollar sign and double curly brackets (${{}}) or single curly brackets ({}) within auto-scripting contexts. In an R context, access to Structr’s built-in functionality is provided via the Structr keyword or dollar sign $ as a global variable.
The JavaScript engine provides special bindings allowing built-in functions to be called directly on the binding object. Built-in functions can be called using Structr.call([Function Name], [Parameters]) and Structr constants can be retrieved using Structr.get('[Constant Name]').
This allows expressions like:
{
$.find('User')
}In any other than the JavaScript context, you are required to use get() and call() to access built-in functions and constants. This results in code like the following example.
{
$.call('find', 'User')
}Example
{
let data = $.get('data');
function reverseString(str) {
return str.split("").reverse().join("");
}
return data.map(d => reverseString(d));
}The return value is determined by using return in the main scope of the script.
Python (Experimental)
A Python scripting context is explicitely defined by ${python{}} (or python{} in an auto-scripting context). In a Python context, access to Structr’s built-in functionality is provided via the Structr keyword as a global variable. Built-in functions can be called using Structr.call([Function Name], [Parameters]) and Structr constants can be retrieved using Structr.get('[Constant Name]').
Example
python{
def getUserNames():
users = map(lambda u: u.name, Structr.call('find','User'))
return users
result = getUserNames()
}The return value is determined by the value of the result variable in the main script scope.
R (Experimental)
An R scripting context is explicitely defined by ${Renjin{}} (or Renjin{} in an auto-scripting context). In an R context, access to Structr’s built-in functionality is provided via the Structr keyword as a global variable. Built-in functions can be called using Structr.call([Function Name], [Parameters]) and Structr constants can be retrieved using Structr.get('[Constant Name]').
Example
Renjin{
c <- Structr$call
g <- Structr$get
data <- g('data')
c('log', c('to_json', data))
result <- data
}The return value is determined by the value of the result variable in the main script scope.
Flows
As an alternative to traditional scripting, Structr offers a visual programming environment called Flows. A Flow consists of Flow Elements that serve different purposes ranging from querying data, processing data, controlling the execution flow and expressing logical conditions. As a whole a Flow can be called like a regular function from Scripting contexts or used as a data source for repeaters in pages.
Note that flows are as powerful as scripts in the sense that any functionality that can be implemented using scripts can also be implemented using flows. Typically an application will contain a combination of scripts and flows to implement the business logic.
The following section provides a deeper look into some of the key aspects of Flows and their inner workings.
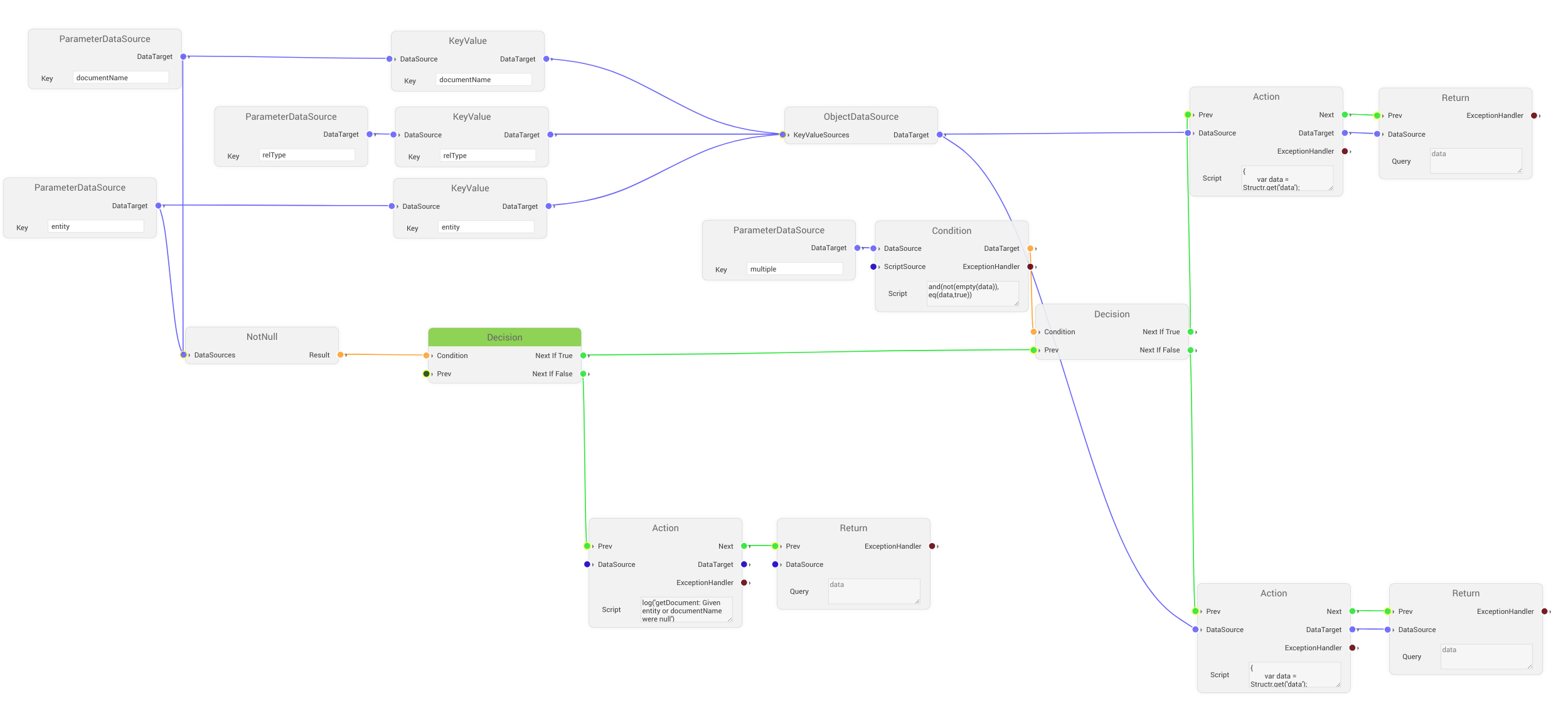
Entry Point
Apart from containing elements at all, a critical requirement for a Flow to be executable is to have a set entry point. Any applicable element can be set as entry point in the editor, as described in the Flow UI documentation.
Execution Flow
When a flow is called, execution will begin at it’s starting element. In case of no entry point being set or no elements being contained, the flow will simply return a null result. Otherwise the Flow Engine will evaluate the starting element and then proceed with the evaluation of the element connected to the initial element as next element. This continues until there is no more next element available, an error has been thrown or the evaluated element is a Return element, in which case the result of the element’s evaluation will be returned. Although this sums up the general execution flow of a Flow, there are notable exceptions to this in the form of specialized elements. For example a Decision element will branch into two execution paths and choose one based on the connected conditional elements. Likewise, a Loop element will enter a different execution path for each element and finally proceeds with the original next element.
Data Flow and Handling
Whenever a Flow Element has a data source socket available, data can be made available to the element. If such an element has a connected data source, it will query data from it’s source before performing it’s own function. The data source itself can also potentially have another data source, which enables data to be recursively constructed from multiple data elements. In case of elements that allow scripting, the acquired data will be made available under the static data key. While this is true for all basic elements, Aggregate is a special case, because it takes two data source inputs and makes them available as data and currentData based on their respective socket.
Conditional Flow
In the same way as data flows behave, whenever an element with connected conditional elements is evaluated, it will ask the connected logic element to evaluate itself. This in turn will recursively resolve all related conditionals.
Exception Handling
Exceptions within flows are handled on three different levels. Firstly if no ExceptionHandler is present in the Flow, every exception will be logged in the Structr log. If an ExceptionHandler is present, but not directly connected to the violating element, it will act as a global ExceptionHandler for the Flow and execute it’s connected actions and contain the related exception data. The last option to handle exceptions within Flows is to directly connect an ExceptionHandler to an element with a supporting socket. This will enable exception handling for the connected elements exclusively and not on a global scale.
Data Model
The data model of a Structr application is stored in the database as a network of nodes and relationships. You can manage it using an interactive UML-like Entity Relationship Model. It consists of a set of types (entities) and their relationships. Since Structr is based on a native graph database, we explicitly distinguish between node and edge types, which are displayed in the schema editor as rectangles with rounded corners (node type) or as green connections (edge type) can be displayed between the node types.
The Data Model is loosely coupled to the database, in particular only those node and relationship types which are defined in the schema are potentitally visible. Nodes and relationships of those types which have an id and type property, as well as having the correct labes are visible to Structr.
Type System
Each type in the schema defines a primary data type, which can hold properties and methods. The type object allows the associated data to be managed automatically via the Structr backend and the REST interface. You can use inheritance to base your data objects on existing built-in types, e.g. group, user, file or folder, to achieve seamless integration into the Structr backend.
Relationships
You can define directed edges between node types and annotate then with a name and cardinality (1:1, 1:n, n:m). Structr uses the structure defined by nodes and relationships as a blueprint for the datastructures in the database. It also takes care that the data is consistent by preventing the creation of invalid structures. In a 1:1 relationship for example, an object can only ever be linked to exactly one other object. If another object is assigned, the previous relationship will be removed. Structr also maintains the type safety of related objects by allowing only those types to be linked to each other that match the schema.
Base Classes
Each node type in the Structr data model can have a base class to inherit existing functionality. If no base class has been explicitly defined, the base class defaults to AbstractNode for node types, and AbstractRelationship for edge types. These two internal classes provide the basic functionality for nodes and edges in Structr.
Inheritance
Types defined in the data model can be reused as base classes themselves. This allows the creation of an inheritance hierarchy to avoid code duplication or to reuse common attributes.
Structr depends on the fact that a database node always has a corresponding type label for each type in the hierarchy. This is especially important in situations when existing nodes in the database should be made available in Structr, e.g. when importing an existing dataset.
Inherited Attributes
AbstractNode and AbstractRelationship define the minimal set of properties necessary for the operation of Structr. Because those two classes will always be at the top of the inheritance chain, the base properties are available in all classes. The most important of these properties is the id property, which contains a 32-character hexadecimal character string.
ID
The id property of all nodes and relationships contains a so-called universally unique identifier (UUID), which is used as the primary key for all purposes in Structr. All objects must contain a valid, unique UUID in their id property to be usable in Structr.
Type
To distinguish the different types, and to identify the actual type of an object in the inheritance hierarchy, the type property must contain the name of the primary type of an object. When an object is loaded from the database, this attribute is used to decide which type from the data model will be used to map the data in the application.
Other Properties
In addition, the time of creation and the last change are stored for each object, as well as some other attributes that are used for internal processing in Structr.
Local Attributes
In addition to the base properties mentioned above, each node and edge type can contain other so-called local attributes such as name, description or size. Apart from primitive data types such as string and number, it is also possible to evaluate script expressions to execute business logic or more complex calculations when accessing them. See the built-in type reference for a list of all possible data types.
Indexing and Constraints
For each local attribute, you can decide whether it is to be included in an index (indexed), is a mandatory attribute (not null) or whether there may only be exactly one object of this type with a certain value in the database (unique) . These validation criteria are automatically monitored by Structr and cause a transaction rollback when violated.
Views
The properties of a schema type can be combined into named groups, called views, which are primarily used to configure the JSON output of the corresponding REST endpoint.
The attributes in a view can be arranged in any order and are then written to the output in exactly that order. You can add and remove attributes to and from views. Views are inherited from the base class to derived classes.
Built-In Views
The base classes provide three preconfigured views.
The public view initially only contains the properties id, name and type and is used as the default view when no view has been explicitly selected. In REST output, the selected view is used to output the root element. For all related elements a view with the same name is used, if defined. Otherwise the properties id, type, name are returned - not the public view.
The custom view contains all properties that are not part of the Structr base data model, i.e. all properties added by you.
The ui view is an internal group that contains all properties required for the operation and functionality of the Structr backend.
Methods
To implement the business logic of an application or to provide reusable blocks of functionality, you can add named methods to any type. Structr distinguishes between methods that are automatically executed at certain events (so-called lifecycle methods) and instance methods that can be called from a scripting context or via a URL.
Contextual Attributes
When you create a relationship between two types in the data model, Structr adds a property to both types which can be used to automatically manage relationships between objects of these types. The cardinality of the relationship determines the type of the contextual property. A 1:n relationship for example results in a list (collection) of objects on one side, and in a single object on the other.
This principle enables Structr to manage object structures very conveniently, since the assignment of one or more objects to each other automatically generates the correct relationship between the nodes involved in the database based on the schema.
REST API
Structr provides a REST API that allows access to data and business logic based on HTTP URLs and methods. The HTTP URLs are called REST endpoints. They read and write data in Javascript Object Notation (JSON).
REST
REST is an acronym that stands for “Representational State Transfer”. The exchange of messages (the representation) between two parties causes a state transition (e.g. creating an object in the database). The basis for this is the HTTP protocol, which specifies a set of actions with clearly defined meaning. In HTTP, these actions are called methods, of which GET and POST are the most commonly used, because a large part of the functionality of the World Wide Web is based on them. Less well-known are the methods PATCH, PUT and DELETE, which together with GET and POST form a complete set of commands for managing data based on HTTP URLs.
HTTP
The Hypertext Transfer Protocol (HTTP) is a stateless communication protocol that is based on the exchange of plain text messages (request and response). A request message consists of a request line that contains the HTTP method, the URL of the requested resource (request URL) and HTTP version, a list of key-value pairs (request headers), and an optional request body. A response message consists of a response line with the HTTP status code, a list of response headers, and an optional response body.
Example Request URL
http://www.example.com/hello.txt
The following HTTP messages are sent when you access the above URL with your browser (or any other HTTP client).
Request Message
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
Response Message
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
Content-Type: text/plain
Hello World!
Request Parameters
The request URL can contain a so-called query component, which starts at the first ? character in the URL and consists of a list of key-value pairs separated by &. These key-value pairs are called request parameters. The following example shows a request URL with two request parameters, name and message.
http://www.example.com?name=hello.txt&message=Hello%20World
URL Encoding
The allowed characters in a URL string are limited, so the client must replace characters that are not allowed in a URL with a special sequence of other characters. This is called URL encoding.
In the example above, the space character is encoded as “% 20”. URL encoding is normally done by the HTTP client, so you don’t have to do it manually. There are however some situations where manual URL encoding is necessary, for example if you build your own URL string in a script. For that purpose Structr provides the urlencode() built-in function. In a Javascript context, the global functions encodeURI() and encodeURIComponent() exist.
Request Headers
HTTP request headers allow you to send metadata along with your request, for example to provide authentication information, to request a different content type, or to influence the behaviour of the server.
The request message in the example above contains three request headers: User-Agent, Host and Accept-Language. You can read more about supported request headers in Structr in the REST Guide.
HTTP Methods
GET
A GET request tells the server to return the content of a particular resource. The location of the requested resource is specified in the request URL, along with HTTP headers that set the desired language, content type, encoding and other metadata. GET requests usually don’t contain a request body, although it is not forbidden by the specification.
The GET method is defined to be read-only, i.e. it must not cause any modification on the server, so the response can be cached for example by a proxy server.
POST
A POST request tells the server to invoke the function that is associated with the location in the request URL. In Structr, a POST request can invoke two different functions, based on the target resource in the URL.
- If the target resource is a Collection Resource, a POST request will create a new object in that collection.
- If the target resource is an Entity Resource that points to a schema method, the method is executed. Any parameters present in the request body will be passed to the method.
- All other resources will return HTTP status 405 Method Not Allowed.
PUT
A PUT request tells the server to replace the contents of the location in the request URL with the contents from the request body. In Structr, a PUT request will only work with a Collection Resource. The implementation of the PUT method in Structr differs from the original specification in that the request body does not replace the original contents, but only changes the values of the properties included in the request. That means that the PUT method in Structr is closer to the specification of PATCH than of PUT.
DELETE
A DELETE request tells the server to delete the contents of the location in the request URL. DELETE can be invoked on Collection Resources and Entity Resources. When the target URL refers to a Collection Resource, all objects that belong to the collection are deleted.
PATCH
A PATCH request tells the server to modify the contents of the location in the request URL according to the instructions in the request body. The specification is very open about what the so-called “patch document” may contain, so the semantics of PATCH are very implementation-specific.
In Structr, a PATCH request on a Collection Resource can modify many objects at once if the request body contains a list of JSON objects with different UUIDs.
HEAD
The HEAD method can be used to get information about the contents of the location in the request URL, without transferring the actual response body. Structr will simply return all the response headers of a GET request, but no response body.
OPTIONS
The OPTIONS method can be used to collect information about the capabilities of an endpoint, without requesting actual content or invoking an action on the server. Structr will simply return all the response headers and an empty result object in response to an OPTIONS request.
TRACE
The TRACE method can be used for testing purposes and is not implemented in Structr.
REST Endpoints
All REST Endpoints in Structr share the same base path, /structr/rest relative to the base URL of your Structr installation. There are two types of REST endpoints in Structr.
Depending on the type of resource, different request methods (GET, PUT, POST, PATCH, DELETE) are allowed.
Authentication
Access to the REST endpoints is prohibited by default and can be obtained through different authentication methods. Please refer to the Security chapter below to learn more about Structr’s Security System, Authentication Headers, Resource Access Grants and HTTP Basic Authentication.
Collection Resources
Collection Resources are HTTP URLs that provide access to a collection of database objects, either nodes or relationships. The path of the resource is determined by the desired type, i.e. you can find the collection of Project nodes in the database at /structr/rest/Project.
Most collection resources in Structr support GET, POST and PATCH for data retrieval, creation and bulk modification of objects, as shown in the following examples.
Examples
The following URLs are examples for collection resource URLs in Structr.
GET http://localhost:8082/structr/rest/User
GET http://localhost:8082/structr/rest/Project
GET http://localhost:8082/structr/rest/Project/c0546a30a79749aeaf364925388e8b60/tasks
Entity Resources
Entity Resources are HTTP URLs that provide access to a single object or function. Entity resource URLs usually end with a UUID to address an object, or the name of a function to invoke. They do not support pagination, sorting or filtering, because they usually contain only a single object.
Examples for GET requests (fetching data)
The following two examples will fetch the node with the provided UUID and return this node as a single JSON object in the result.
GET http://localhost:8082/structr/rest/c0546a30a79749aeaf364925388e8b60
GET http://localhost:8082/structr/rest/Project/c0546a30a79749aeaf364925388e8b60
Examples for POST requests (creating data)
Calling a collection endpoint with the HTTP POST method will create a new node with the schema type in the request. The properties for the node have to be sent in a JSON formatted request body. If more than one node should be created at once, the properties for the nodes have to be sent in a object collection. For each object in the collection a new node will be created in the database.
A new node can be connected to existing nodes in the database by sending the UUID of the nodes that should be connected, either as a String for single cardinality relationships or as a String collection for * cadinality relationships, in the semantically correct remote properties of the new node.
The following example shows how a new node can be created with local properties on the node.
POST http://localhost:8082/structr/rest/Project
Body:
{
"name": "Testproject",
"projectId": "1"
}
Result:
{
"result": "c0546a30a79749aeaf364925388e8b60",
"result_count": 1,
"page_count": 1,
"result_count_time": "0.000068591",
"serialization_time": "0.000299885"
}
The returned UUID of the newly created project node can then be used to link another node to the project node. The following example shows how a relationship between the types Project and ProjectMember can be created.
POST http://localhost:8082/structr/rest/ProjectMember
Body:
{
"name": "TestMember",
"currentProject": "c0546a30a79749aeaf364925388e8b60"
}
Result:
{
"result": "54ebfde1fbef4da2a38e742e55eebc01",
"result_count": 1,
"page_count": 1,
"result_count_time": "0.000068591",
"serialization_time": "0.000299885"
}
For relationships with cardinality 1 the UUID of the connected node has to be sent as a String property. For relationships with cardinality * the UUIDs of the connected nodes have to be provided in a JSON collection of Strings.
To minimize the number of calls to the REST API for data creation, the data can also be created with nested JSON data. Connected nodes that don’t exists yet, can be created and directly connected by sending a nested JSON document to the REST endpoint.
This example show how new nodes can be created and directly connected to another new nodes.
POST http://localhost:8082/structr/rest/Project
Body:
{
"name": "Testproject",
"projectId": "1",
"projectMembers": [
{
// Create new member and connect it directly to new Project
"name": "New Member 1"
},
{
// Create second new member and connect it directly to new Project
"name": "New Member 2"
},
{
// Link existing member to new Project
"id": "54ebfde1fbef4da2a38e742e55eebc01"
}
]
}
Autocreation of nested nodes has to be activated on the relationship type that defines the relationships between the two node types.
Examples for PUT requests (updating data)
To update the properties of a single nodes a PUT request can be sent to the entity resource of that node. The new values of the node have to be provided in the request body as JSON formatted.
Only the provided properties in the request body will be updated to the new value. All other properties of the node will not be changed.
An existing node can be connected to other nodes in the database by sending the UUID of the nodes that should be connected, either as a String for single cardinality relationships or as a String collection for * cadinality relationships, in the semantically correct remote properties of the updated node.
The following example shows how the properties of the node can be updated to new values.
PUT http://localhost:8082/structr/rest/54ebfde1fbef4da2a38e742e55eebc01
Body:
{
"name": "FullMember"
}
Views
Entity resources support view selection exactly like collection resources, so if you want to select the example view of a project, you can do it like in the following examples.
GET http://localhost:8082/structr/rest/c0546a30a79749aeaf364925388e8b60/example
GET http://localhost:8082/structr/rest/Project/c0546a30a79749aeaf364925388e8b60/example
Entity Methods
Methods that are declared and implemented on one specific schema type can be called from the REST API via a HTTP POST request.
The following request will call the method exampleMethod of the schema type Project in the context of the node with the UUID c0546a30a79749aeaf364925388e8b60.
POST http://localhost:8082/structr/rest/Project/c0546a30a79749aeaf364925388e8b60/exampleMethod
will call the method exampleMethod of the schema type Project in the context of the node with the UUID c0546a30a79749aeaf364925388e8b60.
Static Methods
Since version 4.0 Structr also supports static methods on schema types, that can be called without a context entity.
POST http://localhost:8082/structr/rest/Project/exampleStaticMethod
Maintenance Methods
Structr provides some maintenance methods for administrative tasks such as updating the let’s enctrypt certificate or exporting/importing the Structr application. The methods can be called like the following examples.
POST http://localhost:8082/structr/rest/maintenance/letsencrypt
POST http://localhost:8082/structr/rest//maintenance/globalSchemaMethods/updateProjects
Read more
Security
Structr’s security system offers a variety of different approaches for granting access to data stored in the database.
Users and Groups
The basic concept of the security system is based on users and user groups.
- Users can be member of one or many groups.
- Users inherit the permissions of all groups they are member of.
- Groups can be nested into other groups.
- Groups inherit the permissions of all groups they are member of.
Users can log into the application and are given a cookie which Structr can resolve in subsequent requests to the actual user entity in the system. This means that every request to Structr is evaluated in the context of the user who is making the request.
Node-level security
Every entity created by Structr in the underlying graph database is stored as a node with different relationships to other nodes. Following this concept even files, folders, users, groups, pages etc. always have a node representing them in the database and Structr makes use of this for its security system to provide security on the level of those nodes.
The evaluation of the permissions of a user is carried out using a number of checks. If a check is positive and the user has access to the requested node e.g. a Page or a File, Structr will respond with the requested node immediately. This means that the performance of the permission checks varies as it depends on the level of the access grants given to the nodes.
The different levels of node security checks are (in order of execution)
- (isAdmin check)
- Local Visibility Flags on the nodes
- Ownership
- Permission grants
- Graph-based permission resolution
If any check results is positive, the other checks are not executed.
isAdmin Check
The first check Structr makes in the evaluation process for the permissions of a node is the check on the property isAdmin on the user itself. This flag indicates admin rights for the user, which means the user has all possible rights on any node. The check on the isAdmin flag returns immediately and thus all Structr applications are fastest for admin users.
Visibility Flags
When the user accessing a node is no admin user and the first check didn’t return, Structr will check the two flags visibleToPublicUsers and visibleToAuthenticatedUsers on the data nodes themself. The flag visibleToPublicUsers makes a node visible to all users, both to those who are authenticated and the non-authenticated ones. The flag visibleToAuthenticatedUsers only makes a node visible to authenticated users.
Ownership
Ownership of a node is signified by an OWNS relationship (user)-[:OWNS]->(node) between the user and the node. If present, the relationship will give the user full access (read, write, delete, accessControl) to the node.
The OWNS relationship is automatically created by Structr when a user creates a node. For admin users the creation of the relationship can be skipped by setting the flag skipSecurityRelationships on the admin user node. To skip the creation of the relationship for non-admin users a lifecycle method onCreate can be created with the content:
set(this, 'owner', null)
This lifecycle method has to be created on every schema type users should not have a OWNS relationships to.
Permission Grants
Permission grants are signified by a SECURITY relationship (user/group)-[:SECURITY {"allowed": ["read","write","delete","accessControl"]}]->(<a data-id="25248e365e284c88a6234c99b9951311" class="mention">data</a>) between users and/or groups and the data nodes. They indicate wether a user or a user group has access to a node. The SECURITY relationship for users is automatically created by Structr.
The SECURITY relationship can have different combinations of permissions in its allowed attribute:
read | The user has access to the node and can read the node from the database. |
write | The user can alter the node in the database. This permission is also necessary for linking or unlinking the node to other nodes in the graph. |
delete | The user can delete the node from the database. If a node has relationships to other nodes in the database, the user has to have write permissions on those connected nodes, because delete one node in the graph will affect all neighboring nodes. |
accessControl | The user can grant access to other users and user groups. |
The creation of SECURITY relationships can be skipped for admin users by setting the skipSecurityRelationships flag on the admin user node. To skip the creation of the relationship for non-admin users a lifecycle method onCreate can be created with the content:
revoke(me, this, 'read, write, delete, accessControl')
This lifecycle method has to be created on every schema type the creating user should not have a SECURITY relationship to.
Note: If both OWNS and SECURITY are skipped for non-admin users, the user probably has no rights to even see the node after creating it. Using Access Control Functions grant() or copy_permissions() the user/group can get rights to the node.
Graph-based permission resolution
Structr provides graph-based permission resolution to control access rights for non-admin users based on a domain security model. By setting rules for how access rights are propagated over relationships in the graph, the effective access permissions can be controlled.
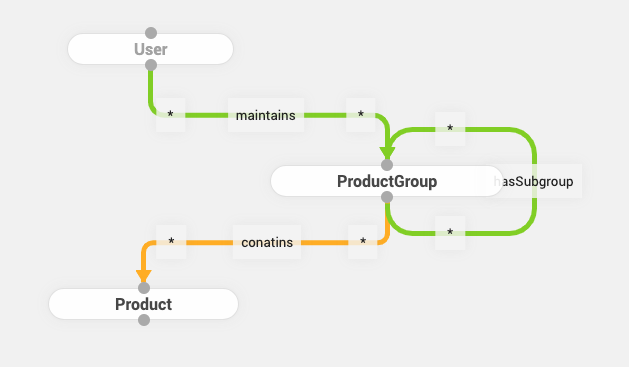
In the above example, the schema is configured in such a way that users with the maintains relationship to a ProductGroup will have access to any Product object in the group they maintain, but not to the subgroups of the given group.
Schema relationships that are configured to allow domain permission resolution are called active relationships. Active relationships are displayed in a different color than normal relationships in the schema editor.
When a non-admin user accesses a private object (e.g. a Product node from the above example schema), Structr tries to find a path which ADDs the requested right or KEEPs the requested right from a node the user has the specific right on.
In detail: We assume that a user who has a read permission grant to a ProductGroup tries to access a Product contained in that group (for which the user does not have direct rights).
Structr will then traverse the active relationship(s) until a path is found which ADDs or KEEPs the requested right.
Successful path evaluation:
- The
(ProductGroup)-[:contains]->(Product)relationship is configured to keep read and write - The effective permissions at the end of the evaluation process are read and write
Unsuccessful path evaluation:
- If a user who has a
readpermission grant to a product that is not contained in the product group he has access to, but in a subgroup of the given group, Structr will not be able to find a connected path of active relationships and will fail the permission resolution. - The user does not have any permission grants set on any node or only visibility flags are set on the data nodes.
Options for permission resolution
| Value | Description |
|---|---|
| NONE | Permission resolution not active |
| SOURCE_TO_TARGET | Permission resolution active from source node to target node (in the direction of the relationship) |
| TARGET_TO_SOURCE | Permission resolution active from target node to source node (in the direction of the relationship) |
| BOTH | Permission resolution active regardless of relationship direction |
Options for read, write, delete and accessControl
| Value | Description |
|---|---|
| Remove | Removes this permission |
| Keep | Keeps this permission |
| Add | Adds this permission |
Hidden Properties
Properties in the Hidden Properties input field are removed from the JSON output of an entity accessed over a permission resolution path. If you for example want to remove the properties price and value from the JSON output of the Product entity in the above example, the hidden properties input field should contain:
price, value
Resource Access Grants
While the security system of Structr is focused on users and their security context (i.e. does the user have access to a given database entity?), the checking of resource access grants is focused on the URL path (the resource) of an HTTP request.
If a user requests all entities of a given schema type via Structr’s REST interface with a call to the URL /structr/rest/SchemaType, Structr will check if the user is logged into the system and if a GET request on the resource SchemaType is permitted for authenticated users. If the user is not logged into the system the permission for non-authenticated users has to be set for that resource.
Only when the permission for the resource is set, Structr will then check if user has grants for the actual database content and the entities of the type SchemaType.
If the Structr log file contains a message like the following:
INFO org.structr.web.auth.UiAuthenticator - Resource access grant found for signature 'SchemaType', but method 'GET' not allowed for public users.
INFO org.structr.web.auth.UiAuthenticator - No resource access grant found for signature 'SchemaType/_Public' (URI: /structr/rest/SchemaType/public)
in newer versions:
INFO org.structr.web.auth.UiAuthenticator - Found no resource access grant for user 'john' and signature 'SchemaType' (URI: /structr/rest/SchemaType)
INFO org.structr.web.auth.UiAuthenticator - Found 1 resource access grant for anonymous users and signature 'SchemaType' (URI: /structr/rest/SchemaType), but method 'GET' not allowed in any of them.
The first message comes in case that the resource access grant with the signature SchemaType exists, but the method GET is not configured to be allowed for public users.
The second message comes in case a resource is requested for which no resource access grant exists at all (in this case a GET request for the view “public” on the type “SchemaType”).
For the first two lines in the above case (< v.4.0) two separate Resource Access Grants would need to be created. One with the signature SchemaType and the GET permission for public users. The other one with the signature SchemaType/_Public.
Beginning in Structr 4.0 Resource Access Grants have been made more flexible. The regular rights management now applies to grants. That means that users have to have read access to the grant object to be able to “use” it. Assigning visibility flags (visibleToPublicUsers, visibleToAuthenticatedUsers) or ACL read rights via users/groups is necessary for this. The other configuration of access flags for HTTP Verbs remain unchanged.
Deployment
If you want to work in a larger team on a Structr application, or want to use a version-control software like git, you can use the deployment functionality of Structr.
Deployment Export
You can export an Structr application to the local host system that Structr is running on. You can follow the export progress in the server log or with the notifications in the Structr UI.
To trigger the export there are multiple options.
Export via Dashboard
Go to the ‘Dashboard’ section of the Structr UI into the tab Deployment. Enter the export location as an absolute path of the local file system into the input field Export application to local directory and click on the button.
Export via Structr console
Open the Structr console in the Structr UI and enter the AdminShell mode. Now enter the command export </export/location/> and confirm with enter.
Export via REST
You can also trigger the export of an Structr application with a REST call.
curl --request POST \
--url http://localhost:8082/structr/rest/maintenance/deploy \
--header 'content-type: application/json' \
--header 'x-user: <AdminUser>' \
--header 'x-password: <AdminUserPassword>' \
--data '{
mode:"export",
target:"</export/location/>"
}'
Export to remote system
If you want to export your Structr application to a remote target system you can do so by clicking the button Export and download application as ZIP file in the ‘Dashboard’ section of the Structr UI under the tab Deployment.
Deployment Import
If you want to import an existing Structr application to a development environment on your local machine or want to deploy a new version on your production systems you can use the import functionality of Structr. You can follow the import progress in the server log or with the notifications in the Structr UI.
To trigger the import there are multiple options.
Import via Dashboard
Go to the ‘Dashboard’ section of the Structr UI into the tab Deployment. Enter the application’s path as an absolute path of the local file system into the input field Import application from local directory and click on the button.
Import via Structr console
Open the Structr console in the Structr UI and enter the AdminShell mode. Now enter the command import </application/path/on/host/system> and confirm with enter.
Import via REST
You can also trigger the import of an Structr application with a REST call.
curl --request POST \
--url http://localhost:8082/structr/rest/maintenance/deploy \
--header 'content-type: application/json' \
--header 'x-user: <AdminUser>' \
--header 'x-password: <AdminUserPassword>' \
--data '{
mode:"import",
source:"</application/path/on/host/system>"
}'
Import from remote URL
If you want to import an Structr application from a remote system you can put the source code of the exported application into a ZIP file on a remote location. Enter that location into the field Import application from URL in the ‘Dashboard’ section of the Structr UI under the tab Deployment and click on the button to start the download and import process.
The ZIP file has to be accessible by the importing Structr instance. Sometimes file permissions or network settings prevent Structr from downloading the ZIP file.
Deployment Format
Structr exports an application to a specific folder and file structure. Each component of the application is exported to a file into an designated folder. Each file has a corresponding entry in a settings json file. A typical Structr application has the following export content:
| folder / file | description |
|---|---|
| components | Contains the shared components of the pages editor of Structr. |
| files | Contains all files out of Sturctr’s virtual filesystem. Folders and files in the virtual filesystem are not being exported by default. If you want to include a folder or file into the export you have to set the flag includeInFrontendExport on each file or folder. Each file or folder will inherit this flag from its parent folder. |
| mail-templates | Contains the mail-templates. |
| modules | Contains the application configuration and definition of additional modules of Structr e.g. the flow engine. |
| pages | Contains the created pages in the pages editor of Structr. |
| schema | Contains the schema definition and code entered in the schema and code section of the Structr UI. |
| security | Contains the resource access grants defined in the security section of the Structr UI. |
| templates | Contains all template elements of the pages editor of Structr. |
| application-configuration-data.json | Contains the configured schema layouts of Structr’s schema editor. |
| components.json | Contains the settings e.g. visiblity flags, contentType or uuid for each file in the components folder of the export. |
| deploy.conf | Contains information about the Structr system that created the export of the application. |
| files.json | Contains the settings e.g. visiblity flags, contentType or uuid for each file in the files folder of the export. |
| localizations.json | Contains the localizations that where created in the localizations section of the Structr UI and that can be used in server side scripting with the localize() function of Structr. |
| mail-templates.json | Contains the settings e.g. visiblity flags, locale or uuid for each file in the mail-templates folder of the export. |
| pages.json | Contains the settings e.g. visiblity flags, contentType or uuid for each file in the pages folder of the export. |
| pre-deploy.conf | Script that is run before deployment import. Use this to create users who are granted access to nodes in the export files. |
| post-deploy.conf | Script that is run after deployment import. Can be used to start any tasks which are necessary after import. |
| sites.json | Contains sites that are configured in the pages section of the Structr UI. |
| templates.json | Contains the settings e.g. visiblity flags, contentType or uuid for each file in the templates folder of the export. |
| widget.json | Contains the widgets that were created in the pages section of the Structr UI. |
pre-deploy.conf
If a file named pre-deploy.conf is present in the application folder that is being imported into a Structr instance, the content of that file will be interpreted as a script by Structr before it imports the actual data. You can use this file to create user groups that are not present in Structr already but are referenced in the visibility settings of any files of the Structr export.
{
let myUserGroup = $.getOrCreate('Group', 'name', 'myUserGroup');
let myNestedUserGroup = $.getOrCreate('Group', 'name', 'myNestedUserGroup');
if (!$.isInGroup(myUserGroup, myNestedUserGroup)) {
$.addToGroup(myUserGroup, myNestedUserGroup);
}
}post-deploy.conf
If a file named post-deploy.conf is present in the application folder that is being imported into a Structr instance, the content of that file will be interpreted as a script by Structr after the application has been imported successfully. You can use this script to create data that has to be present in any copies of your application.
{
let necessaryUser = $.getOrCreate('User', 'name', 'necessaryUser');
let myUserGroup = $.getOrCreate('Group', 'name', 'myUserGroup');
if (!$.isInGroup(myUserGroup, necessaryUser)) {
$.addToGroup(myUserGroup, necessaryUser);
}
}Data Deployment
You can import and export a configurable subset of Structr types to a specific folder and file structure.
To trigger the export there are multiple options.
Data Deployment Export
You can export Structr application data to the local host system that Structr is running on. You can follow the export progress in the server log or with the notifications in the Structr UI.
To trigger the export there are multiple options.
Export via Dashboard
Go to the ‘Dashboard’ section of the Structr UI into the tab Deployment. Enter the export location as an absolute path of the local file system into the input field ‘Export data to local directory’, select the desired export types and click on the Export button.
Export via Structr console
Open the Structr console in the Structr UI and enter the AdminShell mode. Now enter the command export-data </export/location/> <comma-separated list of types> and confirm with enter.
Export via REST
You can also trigger the data export of an Structr application with a REST call.
curl --request POST \
--url http://localhost:8082/structr/rest/maintenance/deployData \
--header 'content-type: application/json' \
--header 'x-user: <AdminUser>' \
--header 'x-password: <AdminUserPassword>' \
--data '{ \
mode:"export", \
target:"</export/location/>", \
types:"<comma-separated list of types>" \
}'
Data Deployment Import
If you want to import application data to a development environment on your local machine or want to deploy a new version on your production systems you can use the data import functionality of Structr. You can follow the import progress in the server log or with the notifications in the Structr UI.
By default, the import runs without any checks. Cardinality is not enforced, validation rules are not applied and onCreate/onSave methods are not run. This is due to the fact that the nodes and relationships are imported sequentially and if those things were enabled, errors would probably stop the import. To update the indexes after an import, simply use the admin-tool “Rebuild all Indexes” in the schema.
To trigger the import there are multiple options.
Import via Dashboard
Go to the ‘Dashboard’ section of the Structr UI into the tab Deployment. Enter the data path as an absolute path of the local file system into the input field Import data from local directory and click on the button.
Import via Structr console
Open the Structr console in the Structr UI and enter the AdminShell mode. Now enter the command import-data </data/path/on/host/system> and confirm with enter.
Import via REST
You can also trigger the import of an application data with a REST call.
curl --request POST \
--url http://localhost:8082/structr/rest/maintenance/deployData \
--header 'content-type: application/json' \
--header 'x-user: <AdminUser>' \
--header 'x-password: <AdminUserPassword>' \
--data '{ \
mode:"import", \
source:"</export/location/>" \
}'
Data Deployment Format
A typical Structr data deployment export has the following export content:
| file/folder | description |
|---|---|
| nodes | Contains all export files for configured node types |
| relationships | Contains all export files for relationships from/to configured node types |
| pre-data-deploy.conf | Script that is run before data deployment import. Use this to create users who are granted access to nodes in the export files. |
| post-data-deploy.conf | Script that is run after data deployment import. Can be used to start any tasks which are necessary after import. |
pre-data-deploy.conf
If a file named pre-data-deploy.conf is present in the data folder that is being imported into a Structr instance, the content of that file will be interpreted as a script by Structr before it imports the actual data. You can use this file to create user groups that are not present in Structr already but are referenced in the visibility settings of any files of the Structr export.
{
let myUserGroup = $.getOrCreate('Group', 'name', 'myUserGroup');
let myNestedUserGroup = $.getOrCreate('Group', 'name', 'myNestedUserGroup');
if (!$.isInGroup(myUserGroup, myNestedUserGroup)) {
$.addToGroup(myUserGroup, myNestedUserGroup);
}
}post-data-deploy.conf
If a file named post-data-deploy.conf is present in the data folder that is being imported into a Structr instance, the content of that file will be interpreted as a script by Structr after the application has been imported successfully. You can use this script to create data that has to be present in any copies of your application.
{
let necessaryUser = $.getOrCreate('User', 'name', 'necessaryUser');
let myUserGroup = $.getOrCreate('Group', 'name', 'myUserGroup');
if (!$.isInGroup(myUserGroup, necessaryUser)) {
$.addToGroup(myUserGroup, necessaryUser);
}
}File Upload
Binary data in form of files can be uploaded to the integrated file system in Structr with a form-data POST request to the upload servlet running on path /structr/upload.
The file to be uploaded has to be put as value for the key file. All other properties defined on the File type can be used to store additional data or link the file directly to an existing data entity in the database.
# example file upload with addional paramter "action" and target directory "parent"
curl --location --request POST 'http://localhost:8082/structr/upload' \
--form 'file=@"/Users/lukas/Pictures/user-example.jpg"' \
--form 'action="ec2947e760bd48b291564ae05a34a3b7"' \
--form 'parent="9aae3f6db3f34a389b84b91e2f4f9761"'